Different Prediction Horizons in PRE
[1]:
import h5py
import scipy
import numpy as np
import torch
import os
import sys
from dataset.dataset_prediction import PRE8dDataset
[2]:
def load(path):
path = path + "/with_imputation"
preds = []
for i in range(10):
preds.append(np.load(path+"/prediction_{}.npy".format(i)))
return np.stack(preds, axis=1)
[3]:
category = []
pred_len = []
mse_list = []
mae_list = []
predictions for 1 year (PRE)
[4]:
base_dir = "./log/prediction_46_46/PRE/"
prediction_xg = np.load(base_dir+"XGBoost/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_our = load(base_dir+"STIMP")
prediction_mtgnn = np.load(base_dir+"MTGNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_tsmixer = np.load(base_dir+"TSMixer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_crossformer = np.load(base_dir+"CrossFormer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_iTransformer = np.load(base_dir+"iTransformer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_predrnn = np.load(base_dir+"PredRNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_pde = np.load("./data/PRE/cmoms.npy")
[5]:
import argparse
from torch.utils.data import DataLoader
parser = argparse.ArgumentParser(description='Prediction')
parser.add_argument('--area', type=str, default='PRE', help='which bay area we focus')
parser.add_argument('--method', type=str, default='GraphTransformer', help='which bay area we focus')
parser.add_argument('--index', type=int, default=0, help='which dataset we use')
parser.add_argument('--epochs', type=int, default=200, help='epochs')
parser.add_argument('--batch_size', type=int, default=8, help='batch size')
parser.add_argument('--lr', type=float, default=1e-4, help='learning rate')
parser.add_argument('--wd', type=float, default=1e-6, help='weight decay')
parser.add_argument('--test_freq', type=int, default=20, help='test per n epochs')
parser.add_argument('--hidden_dim', type=int, default=8)
parser.add_argument('--in_len', type=int, default=46)
parser.add_argument('--out_len', type=int, default=46)
parser.add_argument('--missing_ratio', type=float, default=0.1)
config = parser.parse_args([])
test_dloader = DataLoader(PRE8dDataset(config, mode='test'), config.batch_size, shuffle=False)
labels_list = []
label_masks_list = []
for test_step, (datas, data_ob_masks, data_gt_masks, labels, label_masks) in enumerate(test_dloader):
labels_list.append(labels[:,:,0])
label_masks_list.append(label_masks[:,:,0])
labels = torch.cat(labels_list, 0)
label_masks = torch.cat(label_masks_list, 0)
[6]:
label_masks = label_masks.squeeze()
labels = labels.squeeze()
prediction_our = torch.from_numpy(prediction_our).squeeze()
prediction_xg = torch.from_numpy(prediction_xg).squeeze()
prediction_tsmixer = torch.from_numpy(prediction_tsmixer).squeeze()
prediction_mtgnn = torch.from_numpy(prediction_mtgnn).squeeze()
prediction_crossformer = torch.from_numpy(prediction_crossformer).squeeze()
prediction_iTransformer = torch.from_numpy(prediction_iTransformer).squeeze()
prediction_predrnn = torch.from_numpy(prediction_predrnn).squeeze()
prediction_pde = torch.from_numpy(prediction_pde)
prediction_pde_oneyear = [prediction_pde[i:i+46] for i in range(322-46)]
prediction_pde_oneyear = torch.stack(prediction_pde_oneyear, dim=0)
[7]:
mse_our= (((prediction_our.mean(1)- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_our))
mse_xg = (((prediction_xg- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_xg))
mse_tsmixer = (((prediction_tsmixer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_tsmixer))
mse_crossformer = (((prediction_crossformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_crossformer))
mse_mtgnn = (((prediction_mtgnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_mtgnn))
mse_iTransformer = (((prediction_iTransformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_iTransformer))
mse_predrnn = (((prediction_predrnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_predrnn))
mse_pde = (((prediction_pde_oneyear - labels[:276])*label_masks[:276])**2).sum([0,1])/(label_masks[:276].sum([0,1])+1e-5)
print(np.nanmean(mse_pde))
mse_our[mse_our==0]=np.nan
mse_xg[mse_xg==0]=np.nan
mse_crossformer[mse_crossformer==0]=np.nan
mse_mtgnn[mse_mtgnn==0]=np.nan
mse_tsmixer[mse_tsmixer==0]=np.nan
mse_iTransformer[mse_iTransformer==0]=np.nan
mse_predrnn[mse_predrnn==0]=np.nan
mse_pde[mse_pde==0]=np.nan
category.extend(["CMOMS" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["XGBoost" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["MTGNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["CrossFormer" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["TSMixer" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["iTransformer" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["PredRNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
category.extend(["STIMP" for i in range(mse_our.shape[-1])])
pred_len.extend(["one" for i in range(mse_our.shape[-1])])
mse_list.extend([mse_pde.numpy(), mse_xg.numpy(), mse_mtgnn.numpy(), mse_crossformer.numpy(), mse_tsmixer.numpy(), mse_iTransformer.numpy(), mse_predrnn.numpy(), mse_our.numpy()])
0.073147625
0.18426761
0.13500492
0.14994895
0.17269786
0.17230226
0.08720154
0.36229101456665624
[8]:
mae_our= (np.abs((prediction_our.mean(1)- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_our))
mae_xg = (np.abs((prediction_xg- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_xg))
mae_tsmixer = (np.abs((prediction_tsmixer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_tsmixer))
mae_crossformer = (np.abs((prediction_crossformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_crossformer))
mae_mtgnn = (np.abs((prediction_mtgnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_mtgnn))
mae_iTransformer = (np.abs((prediction_iTransformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_iTransformer))
mae_predrnn = (np.abs((prediction_predrnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_predrnn))
mae_pde = (np.abs((prediction_pde_oneyear - labels[:276])*label_masks[:276])).sum([0,1])/(label_masks[:276].sum([0,1])+1e-5)
print(np.nanmean(mae_pde))
mae_our[mae_our==0]=np.nan
mae_xg[mae_xg==0]=np.nan
mae_crossformer[mae_crossformer==0]=np.nan
mae_mtgnn[mae_mtgnn==0]=np.nan
mae_tsmixer[mae_tsmixer==0]=np.nan
mae_iTransformer[mae_iTransformer==0]=np.nan
mae_predrnn[mae_predrnn==0]=np.nan
mae_pde[mae_pde==0]=np.nan
mae_list.extend([mae_pde.numpy(), mae_xg.numpy(), mae_mtgnn.numpy(), mae_crossformer.numpy(), mae_tsmixer.numpy(), mae_iTransformer.numpy(), mae_predrnn.numpy(), mae_our.numpy()])
0.19770662
0.3561439
0.29954606
0.31450367
0.34601954
0.34509417
0.21909997
0.4754564140362484
prediction two year
[9]:
base_dir = "./log/prediction_46_92/PRE/"
prediction_xg = np.load(base_dir+"XGBoost/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_our = load(base_dir+"STIMP")
prediction_mtgnn = np.load(base_dir+"MTGNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_tsmixer = np.load(base_dir+"TSMixer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_crossformer = np.load(base_dir+"CrossFormer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_iTransformer = np.load(base_dir+"iTransformer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_predrnn = np.load(base_dir+"PredRNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_pde = np.load("./data/PRE/cmoms.npy")
[10]:
config.out_len = 92
test_dloader = DataLoader(PRE8dDataset(config, mode='test'), config.batch_size, shuffle=False)
labels_list = []
label_masks_list = []
for test_step, (datas, data_ob_masks, data_gt_masks, labels, label_masks) in enumerate(test_dloader):
labels_list.append(labels[:,:,0])
label_masks_list.append(label_masks[:,:,0])
labels = torch.cat(labels_list, 0)
label_masks = torch.cat(label_masks_list, 0)
[11]:
label_masks = label_masks.squeeze()
labels = labels.squeeze()
prediction_our = torch.from_numpy(prediction_our).squeeze()
prediction_xg = torch.from_numpy(prediction_xg).squeeze()
prediction_tsmixer = torch.from_numpy(prediction_tsmixer).squeeze()
prediction_mtgnn = torch.from_numpy(prediction_mtgnn).squeeze()
prediction_crossformer = torch.from_numpy(prediction_crossformer).squeeze()
prediction_iTransformer = torch.from_numpy(prediction_iTransformer).squeeze()
prediction_predrnn = torch.from_numpy(prediction_predrnn).squeeze()
prediction_pde = torch.from_numpy(prediction_pde)
prediction_pde_twoyear = [prediction_pde[i:i+92] for i in range(322-92)]
prediction_pde_twoyear = torch.stack(prediction_pde_twoyear, dim=0)
[12]:
mse_our= (((prediction_our.mean(1)- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_our))
mse_xg = (((prediction_xg- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_xg))
mse_tsmixer = (((prediction_tsmixer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_tsmixer))
mse_crossformer = (((prediction_crossformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_crossformer))
mse_mtgnn = (((prediction_mtgnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_mtgnn))
mse_iTransformer = (((prediction_iTransformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_iTransformer))
mse_predrnn = (((prediction_predrnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_predrnn))
mse_pde = (((prediction_pde_twoyear - labels[:230])*label_masks[:230])**2).sum([0,1])/(label_masks[:230].sum([0,1])+1e-5)
print(np.nanmean(mse_pde))
mse_our[mse_our==0]=np.nan
mse_xg[mse_xg==0]=np.nan
mse_crossformer[mse_crossformer==0]=np.nan
mse_mtgnn[mse_mtgnn==0]=np.nan
mse_tsmixer[mse_tsmixer==0]=np.nan
mse_iTransformer[mse_iTransformer==0]=np.nan
mse_predrnn[mse_predrnn==0]=np.nan
mse_pde[mse_pde==0]=np.nan
category.extend(["CMOMS" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["XGBoost" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["MTGNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["CrossFormer" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["TSMixer" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["iTransformer" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["PredRNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
category.extend(["STIMP" for i in range(mse_our.shape[-1])])
pred_len.extend(["two" for i in range(mse_our.shape[-1])])
mse_list.extend([mse_pde.numpy(), mse_xg.numpy(), mse_mtgnn.numpy(), mse_crossformer.numpy(), mse_tsmixer.numpy(), mse_iTransformer.numpy(), mse_predrnn.numpy(), mse_our.numpy()])
0.07450346
0.18809351
0.13591254
0.14446642
0.15794146
0.16716537
0.18573698
0.4082120755015494
[13]:
mae_our= (np.abs((prediction_our.mean(1)- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_our))
mae_xg = (np.abs((prediction_xg- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_xg))
mae_tsmixer = (np.abs((prediction_tsmixer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_tsmixer))
mae_crossformer = (np.abs((prediction_crossformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_crossformer))
mae_mtgnn = (np.abs((prediction_mtgnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_mtgnn))
mae_iTransformer = (np.abs((prediction_iTransformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_iTransformer))
mae_predrnn = (np.abs((prediction_predrnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_predrnn))
mae_pde = (np.abs((prediction_pde_twoyear - labels[:230])*label_masks[:230])).sum([0,1])/(label_masks[:230].sum([0,1])+1e-5)
print(np.nanmean(mae_pde))
mae_our[mae_our==0]=np.nan
mae_xg[mae_xg==0]=np.nan
mae_crossformer[mae_crossformer==0]=np.nan
mae_mtgnn[mae_mtgnn==0]=np.nan
mae_tsmixer[mae_tsmixer==0]=np.nan
mae_iTransformer[mae_iTransformer==0]=np.nan
mae_predrnn[mae_predrnn==0]=np.nan
mae_pde[mae_pde==0]=np.nan
mae_list.extend([mae_pde.numpy(), mae_xg.numpy(), mae_mtgnn.numpy(), mae_crossformer.numpy(), mae_tsmixer.numpy(), mae_iTransformer.numpy(), mae_predrnn.numpy(), mae_our.numpy()])
0.20153603
0.35937086
0.29741377
0.30319464
0.32018575
0.33398306
0.35080168
0.4994291208859563
prediction three years
[14]:
base_dir = "./log/prediction_46_138/PRE/"
prediction_xg = np.load(base_dir+"XGBoost/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_our = load(base_dir+"STIMP")
prediction_mtgnn = np.load(base_dir+"MTGNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_tsmixer = np.load(base_dir+"TSMixer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_crossformer = np.load(base_dir+"CrossFormer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_iTransformer = np.load(base_dir+"iTransformer/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_predrnn = np.load(base_dir+"PredRNN/without_imputation/prediction_0.npy", allow_pickle=True)
prediction_pde = np.load("./data/PRE/cmoms.npy")
[15]:
config.out_len = 138
test_dloader = DataLoader(PRE8dDataset(config, mode='test'), config.batch_size, shuffle=False)
labels_list = []
label_masks_list = []
for test_step, (datas, data_ob_masks, data_gt_masks, labels, label_masks) in enumerate(test_dloader):
labels_list.append(labels[:,:,0])
label_masks_list.append(label_masks[:,:,0])
labels = torch.cat(labels_list, 0)
label_masks = torch.cat(label_masks_list, 0)
[16]:
label_masks = label_masks.squeeze()
labels = labels.squeeze()
prediction_our = torch.from_numpy(prediction_our).squeeze()
prediction_xg = torch.from_numpy(prediction_xg).squeeze()
prediction_tsmixer = torch.from_numpy(prediction_tsmixer).squeeze()
prediction_mtgnn = torch.from_numpy(prediction_mtgnn).squeeze()
prediction_crossformer = torch.from_numpy(prediction_crossformer).squeeze()
prediction_iTransformer = torch.from_numpy(prediction_iTransformer).squeeze()
prediction_predrnn = torch.from_numpy(prediction_predrnn).squeeze()
prediction_pde = torch.from_numpy(prediction_pde)
prediction_pde_threeyear = [prediction_pde[i:i+138] for i in range(322-138)]
prediction_pde_threeyear = torch.stack(prediction_pde_threeyear, dim=0)
[17]:
mse_our= (((prediction_our.mean(1)- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_our))
mse_xg = (((prediction_xg- labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_xg))
mse_tsmixer = (((prediction_tsmixer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_tsmixer))
mse_crossformer = (((prediction_crossformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_crossformer))
mse_mtgnn = (((prediction_mtgnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_mtgnn))
mse_iTransformer = (((prediction_iTransformer - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_iTransformer))
mse_predrnn = (((prediction_predrnn - labels)*label_masks)**2).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mse_predrnn))
mse_pde = (((prediction_pde_threeyear - labels[:184])*label_masks[:184])**2).sum([0,1])/(label_masks[:184].sum([0,1])+1e-5)
print(np.nanmean(mse_pde))
mse_our[mse_our==0]=np.nan
mse_xg[mse_xg==0]=np.nan
mse_crossformer[mse_crossformer==0]=np.nan
mse_mtgnn[mse_mtgnn==0]=np.nan
mse_tsmixer[mse_tsmixer==0]=np.nan
mse_iTransformer[mse_iTransformer==0]=np.nan
mse_predrnn[mse_predrnn==0]=np.nan
mse_pde[mse_pde==0]=np.nan
category.extend(["CMOMS" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["XGBoost" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["MTGNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["CrossFormer" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["TSMixer" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["iTransformer" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["PredRNN" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
category.extend(["STIMP" for i in range(mse_our.shape[-1])])
pred_len.extend(["three" for i in range(mse_our.shape[-1])])
mse_list.extend([mse_pde.numpy(), mse_xg.numpy(), mse_mtgnn.numpy(), mse_crossformer.numpy(), mse_tsmixer.numpy(), mse_iTransformer.numpy(), mse_predrnn.numpy(), mse_our.numpy()])
0.07705605
0.18486586
0.1411465
0.14870067
0.18185502
0.1703397
0.22432613
0.41801514200460854
[18]:
mae_our= (np.abs((prediction_our.mean(1)- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_our))
mae_xg = (np.abs((prediction_xg- labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_xg))
mae_tsmixer = (np.abs((prediction_tsmixer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_tsmixer))
mae_crossformer = (np.abs((prediction_crossformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_crossformer))
mae_mtgnn = (np.abs((prediction_mtgnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_mtgnn))
mae_iTransformer = (np.abs((prediction_iTransformer - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_iTransformer))
mae_predrnn = (np.abs((prediction_predrnn - labels)*label_masks)).sum([0,1])/(label_masks.sum([0,1])+1e-5)
print(np.nanmean(mae_predrnn))
mae_pde = (np.abs((prediction_pde_threeyear - labels[:184])*label_masks[:184])).sum([0,1])/(label_masks[:184].sum([0,1])+1e-5)
print(np.nanmean(mae_pde))
mae_our[mae_our==0]=np.nan
mae_xg[mae_xg==0]=np.nan
mae_crossformer[mae_crossformer==0]=np.nan
mae_mtgnn[mae_mtgnn==0]=np.nan
mae_tsmixer[mae_tsmixer==0]=np.nan
mae_iTransformer[mae_iTransformer==0]=np.nan
mae_predrnn[mae_predrnn==0]=np.nan
mae_pde[mae_pde==0]=np.nan
mae_list.extend([mae_pde.numpy(), mae_xg.numpy(), mae_mtgnn.numpy(), mae_crossformer.numpy(), mae_tsmixer.numpy(), mae_iTransformer.numpy(), mae_predrnn.numpy(), mae_our.numpy()])
0.20486438
0.35579094
0.30123833
0.3114494
0.35605833
0.336675
0.3990384
0.5056797745910621
[19]:
import pandas as pd
import numpy as np
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
new_pred_len = []
data = {'mse': np.concatenate(mse_list, axis=0),
'methods':category,
'prediction years':pred_len}
data = pd.DataFrame.from_dict(data)
sns.set(style="whitegrid")
plt.xticks(rotation=30)
color_palette = ["#FF0000", "#8C564B", "#2CA02C", "#FFCC00", "#1F77B4", "#9467BD","#FF7F0E", "#E377C2"][::-1]
g = sns.catplot(x="prediction years", y="mse", hue="methods", kind="point", data=data, palette=sns.color_palette(color_palette))
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("prediction years",fontsize=16)
plt.ylabel("MSE",fontsize=16)
# g = sns.lineplot(x="prediction years", y="mse", hue="methods", data=data, palette=sns.color_palette(color_palette), errorbar=None, marker='o', markersize=8)
[19]:
Text(62.853375, 0.5, 'MSE')


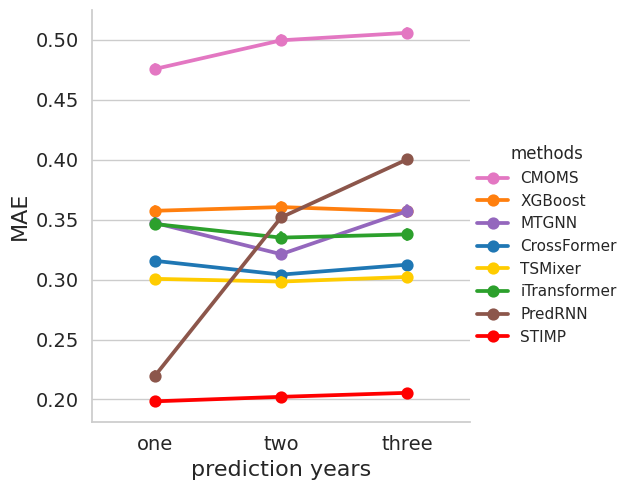
[20]:
import pandas as pd
import numpy as np
import seaborn as sns
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data = {'mae': np.concatenate(mae_list, axis=0),
'methods':category,
'prediction years':pred_len}
data = pd.DataFrame.from_dict(data)
sns.set(style="whitegrid")
plt.xticks(rotation=30)
color_palette = ["#FF0000", "#8C564B", "#2CA02C", "#FFCC00", "#1F77B4", "#9467BD","#FF7F0E", "#E377C2"][::-1]
g = sns.catplot(x="prediction years", y="mae", hue="methods", kind="point", data=data, palette=sns.color_palette(color_palette))
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("prediction years",fontsize=16)
plt.ylabel("MAE",fontsize=16)
[20]:
Text(62.853375, 0.5, 'MAE')